

R入门
基础语法
Hello World
myString<-"Hello"
print(myString)
最新版本的 R 语言的赋值可以使用左箭头 <-、等号 = 、右箭头 -> 赋值
变量
R 语言的有效的变量名称由字母,数字以及点号 . 或下划线 _ 组成
变量名称以字母或点开头
ls()查看已经定义的变量
rm()删除已经定义的变量
print() 是 R 语言的输出函数
list() 元素的集合,元素可以是不同类型的
rm(list = ls()) 从环境中删除所有变量
> ls()
[1] "hhh" "myString"
> print(ls())
[1] "hhh" "myString"
> rm(hhh)
> ls()
[1] "myString"
cat(1, "加", 1, "等于", 2, '\n') 输出结果拼接
输出内容到文件
cat() 函数支持直接输出结果到文件 ,file参数可以为相对路径和绝对路径
cat("RUNOOB", file="/Users/runoob/runoob-test/r_test.txt")
cat("Hello", file="G:\\R\\test.r")
sink() 函数可以把控制台文字输出到文件
语句执行以后,任何控制台上的输出都会被写入到 “/Users/runoob/runoob-test/r_test.txt” 文件中去,控制台将不会显示输出。如果想要保留控制台的输出,可以设置 split 属性:
注意:这个操作是"覆盖写入"操作,会直接清除原有的文件内容。
想要取消输出到文件可以使用无参数的
sink()
sink("/Users/runoob/runoob-test/r_test.txt")
sink("/Users/runoob/runoob-test/r_test.txt", split=TRUE)
sink("r_test.txt", split=TRUE) # 控制台同样输出
for (i in 1:5)
print(i)
sink() # 取消输出到文件
sink("r_test.txt", append=TRUE) # 控制台不输出,追加写入文件
print("RUNOOB")
从文件读取内容到字符串
R 语言最方便的地方就是可以将数据结构直接保存到文件中去,而且支持保存为 CSV、Excel 表格等形式,并且支持直接地读取。
- 如果纯粹的想将某个文件中的内容读取为字符串,可以使用
readLines函数 , 所读取的文本文件每一行 (包括最后一行) 的结束必须有换行符,否则会报错
readLines("/Users/runoob/runoob-test/r_test.txt")
工作目录
getwd(): 获取当前工作目录setwd(): 设置当前工作目录
# 当前工作目录
print(getwd())
# 设置当前工作目录
setwd("/Users/runoob/runoob-test2")
注释
- R 语言只支持单行注释,注释符号为 #
多行注释写法
if(FALSE) {
"
这是一个多行注释的实例
注释内容放在单引号或双引号之间
"
}
交互式编程
配置好环境变量后,CMD中输入R即可进入交互式编程窗口,输入q()退出
R 语言文件后缀为 .R , 命令行窗口使用 Rscript test.R执行脚本
基础运算
数学运算符
| 符号 | 含义 |
|---|---|
| () | 括号 |
| ^ | 乘方运算 |
| %% | 整数求余 |
| %/% | 整除 |
| * | 乘法 |
| / | 除法 |
| + | 加法 |
| - | 减法 |
关系运算符
关系运算符比较两个向量,将第一向量与第二向量的每个元素进行比较,结果返回一个布尔值 , 对两列数据逐个比较
| 运算符 | 描述 |
|---|---|
| > | 判断第一个向量的每个元素是否大于第二个向量的相对应元素。 |
| < | 判断第一个向量的每个元素是否小于第二个向量的相对应元素。 |
| == | 判断第一个向量的每个元素是否等于第二个向量的相对应元素。 |
| != | 判断第一个向量的每个元素是否不等于第二个向量的相对应元素。 |
| >= | 判断第一个向量的每个元素是否大于等于第二个向量的相对应元素。 |
| <= | 判断第一个向量的每个元素是否小于等于第二个向量的相对应元素。 |
v <- c(2,4,6,9)
t <- c(1,4,7,9)
print(v>t)
print(v < t)
print(v == t)
print(v!=t)
print(v>=t)
print(v<=t)
[1] TRUE FALSE FALSE FALSE
[1] FALSE FALSE TRUE FALSE
[1] FALSE TRUE FALSE TRUE
[1] TRUE FALSE TRUE FALSE
[1] TRUE TRUE FALSE TRUE
[1] FALSE TRUE TRUE TRUE
逻辑运算符
非 0 的数字(正数或负数)都为 TRUE
逻辑运算符比较两个向量,将第一向量与第二向量的每个元素进行比较,结果返回一个布尔值
| 运算符 | 描述 |
|---|---|
| & | 元素逻辑与运算符,将第一个向量的每个元素与第二个向量的相对应元素进行组合,如果两个元素都为 TRUE,则结果为 TRUE,否则为 FALSE。 |
| | | 元素逻辑或运算符,将第一个向量的每个元素与第二个向量的相对应元素进行组合,如果两个元素中有一个为 TRUE,则结果为 TRUE,如果都为 FALSE,则返回 FALSE。 |
| ! | 逻辑非运算符,返回向量每个元素相反的逻辑值,如果元素为 TRUE 则返回 FALSE,如果元素为 FALSE 则返回 TRUE。 |
| && | 逻辑与运算符,只对两个向量对第一个元素进行判断,如果两个元素都为 TRUE,则结果为 TRUE,否则为 FALSE。 |
| || | 逻辑或运算符,只对两个向量对第一个元素进行判断,如果两个元素中有一个为 TRUE,则结果为 TRUE,如果都为 FALSE,则返回 FALSE。 |
v <- c(3,1,TRUE,2+3i)
t <- c(4,1,FALSE,2+3i)
print(v&t)
print(v|t)
print(!v)
# &&、||只对第一个元素进行比较
v <- c(3,0,TRUE,2+2i)
t <- c(1,3,TRUE,2+3i)
print(v&&t)
v <- c(0,0,TRUE,2+2i)
t <- c(0,3,TRUE,2+3i)
print(v||t)
赋值运算符
| 运算符 | 描述 |
|---|---|
| <− = <<− | 向左赋值。 |
| −> −>> | 向右赋值。 |
# 向左赋值
v1 <- c(3,1,TRUE,"runoob")
v2 <<- c(3,1,TRUE,"runoob")
v3 = c(3,1,TRUE,"runoob")
print(v1)
print(v2)
print(v3)
# 向右赋值
c(3,1,TRUE,"runoob") -> v1
c(3,1,TRUE,"runoob") ->> v2
print(v1)
print(v2)
其他运算符
| 运算符 | 描述 |
|---|---|
| : | 冒号运算符,用于创建一系列数字的向量。 |
| %in% | 用于判断元素是否在向量里,返回布尔值,有的话返回 TRUE,没有返回 FALSE。 |
| %*% | 用于矩阵与它转置的矩阵相乘。 |
# 1 到 10 的向量
v <- 1:10
print(v)
# 判断数字是否在向量 v 中
v1 <- 3
v2 <- 15
print(v1 %in% v)
print(v2 %in% v)
# 矩阵与它转置的矩阵相乘
M = matrix( c(2,6,5,1,10,4), nrow = 2,ncol = 3,byrow = TRUE)
t = M %*% t(M)
print(t)
数学函数
| 函数 | 说明 |
|---|---|
| sqrt(n) | n的平方根 |
| exp(n) | 自然常数e的n次方, |
| log(m,n) | 以n为底m的对数,返回n的几次方等于m |
| log10(m) | 相当于log(m,10) |
| 名称 | 参数模型 | 含义 |
|---|---|---|
| round | (n) | 对 n 四舍五入取整 当取整位是偶数的时候,五也会被舍去 |
| (n, m) | 对 n 保留 m 位小数四舍五入 | |
| ceiling | (n) | 对 n 向上取整 |
| floor | (n) | 对 n 向下取整 |
> round(1.114514)
[1] 1
> round(1.114514,4)
[1] 1.1145
> ceiling(114.514)
[1] 115
> floor(1.3)
[1] 1
#三角函数
> sin(pi/6)
[1] 0.5
> cos(pi/4)
[1] 0.7071068
> tan(pi/3)
[1] 1.732051
> asin(0.5)
[1] 0.5235988
> acos(0.7071068)
[1] 0.7853981
> atan(1.732051)
[1] 1.047198
# 正态分布函数
> dnorm(0)
[1] 0.3989423
> pnorm(0)
[1] 0.5
> qnorm(0.95)
[1] 1.644854
> rnorm(3, 5, 2) # 产生 3 个平均值为 5,标准差为 2 的正态随机数
[1] 4.177589 6.413927 4.206032
字都以 norm 结尾,代表"正态分布"。
- d - 概率密度函数
- p - 概率密度积分函数(从无限小到 x 的积分)
- q - 分位数函数
- r - 随机数函数(常用于概率仿真)
判断 循环
判断
if("weibo" %in% x) {
print("第一个 if")
} else if ("runoob" %in% x) {
print("第二个 if")
} else {
print("没有找到")
}
switch 语句必须遵循下面的规则:
- switch 语句中的 expression 是一个常量表达式,可以是整数或字符串,如果是整数则返回对应的 case 位置值,如果整数不在位置的范围内则返回 NULL。
- 如果匹配到多个值则返回第一个。
- expression如果是字符串,则对应的是 case 中的变量名对应的值,没有匹配则没有返回值。
- switch 没有默认参数可用
switch(expression, case1, case2, case3....)
x <- switch(
3,
"google",
"runoob",
"taobao",
"weibo"
)
print(x)
[1] "taobao"
you.like<-"runoob"
switch(you.like, google="www.google.com", runoob = "www.runoob.com", taobao = "www.taobao.com")
[1] "www.runoob.com"
循环
R 语言提供的循环类型有:
- repeat 循环
- while 循环
- for 循环
R 语言提供的循环控制语句有:
- break 语句
- Next 语句
repeat
repeat 循环会一直执行代码,直到条件语句为 true 时才退出循环,退出要使用到 break 语句。
repeat {
// 相关代码
if(condition) {
break
}
}
v <- c("Google","Runoob")
cnt <- 2
repeat {
print(v)
cnt <- cnt+1
if(cnt > 5) {
break
}
}
while
只要给定的条件为 true,R 语言中的 while 循环语句会重复执行一个目标语句。
while(condition)
{
statement(s);
}
for
R 编程语言中 for 循环语句可以重复执行指定语句,重复次数可在 for 语句中控制。
for (value in vector) {
statements
}
break
与其他语言用法相同
next
next 语句用于跳过当前循环,开始下一次循环(类似其他语言的 continue)。
函数
函数创建时可以为参数指定默认值,如果调用的时候不传递参数就会使用默认值
function_name <- function(arg_1, arg_2, ...) {
// 函数体
}
# 定义一个函数,用于计数一个系列到平方值
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}
# 调用函数,并传递参数
new.function(6)
# 创建带默认参数的函数
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
# 调用函数,但不传递参数,会使用默认的
new.function()
# 调用函数,传递参数
new.function(9,5)
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
# 调用函数,不需要传递参数
new.function()
new.function <- function(a,b,c) {
result <- a * b + c
print(result)
}
# 不带参数名
new.function(5,3,11)
# 带参数名
new.function(a = 11, b = 5, c = 3)
- function_name : 为函数名
- arg_1, arg_2, … : 形式参数列表
- 函数返回值使用 return()。
| 常用函数 | 作用 |
|---|---|
| sort() | 排序 |
| rev() | 倒序 |
| table() | 值出现的次数 |
| unique() | 删除重复的元素 /行 |
| length(o) | 显示对象中元素/成分的数量 |
| names(o) | 显示某个对象中各成分的名称 |
| c(o1,o2,…) | 将对象合并入一个向量 |
| cbind(o1,o2,…) | 按列合并对象 |
| rbind(o1,o2,…) | 按行合并对象 |
| head(o) | 列出对象的开始部分 |
| tail(o) | 列出对象的结尾部分 |
| fix(o) | 直接编辑对象 |
| newo<-edit(o) | 编辑对象并存到newo中 |
数据类型
简介
- 数字支持科学计数法
- 布尔值 “TRUE” “FALSE”
- 字符串可以用单引号也可以用双引号
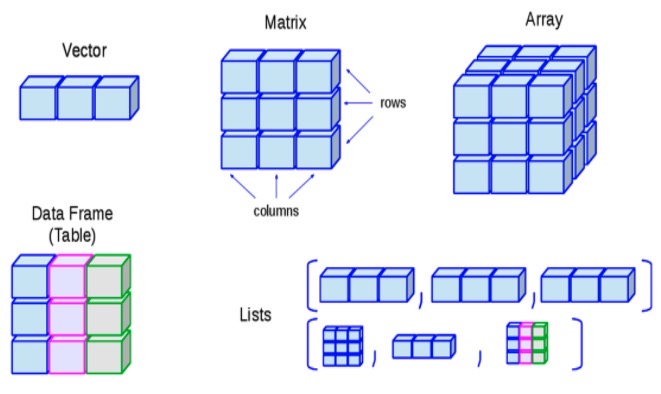
- 向量(vector)
- 列表(list)
- 矩阵(matrix)
- 数组(array)
- 因子(factor)
- 数据框(data.frame)
向量
向量从数据结构上看就是一个线性表,可以看成一个数组。
c() 是一个创造向量的函数。
向量索引从1开始
向量的生成可以用 c() 函数生成,也可以用 min:max 运算符生成连续的序列
向量中常会用到 NA 和 NULL
- NA 代表的是"缺失",NULL 代表的是"不存在"。
- NA 缺失就像占位符,代表这里没有一个值,但位置存在。
- NULL 代表的就是数据不存在。
> a = c(3, 4)
> b = c(5, 0)
> a + b
[1] 8 4
> a = c(10, 20, 30, 40, 50)
> a[2]
[1] 20
> a[1:4] # 取出第 1 到 4 项,包含第 1 和第 4 项
[1] 10 20 30 40
> a[c(1, 3, 5)] # 取出第 1, 3, 5 项
[1] 10 30 50
> a[c(-1, -5)] # 去掉第 1 和第 5 项
[1] 20 30 40
> a[-c(1, 3, 5)]
[1] 20 40
> a[-c(-1,-3)]
[1] 10 30
> a-3
[1] 7 17 27 37 47
> a = c(1, 3, 5, 2, 4, 6)
> sort(a) #排序
[1] 1 2 3 4 5 6
> rev(a) #倒序
[1] 6 4 2 5 3 1
> order(a) #order() 函数返回的是一个向量排序之后的下标向量。
[1] 1 4 2 5 3 6
> a[order(a)]
[1] 1 2 3 4 5 6
| 函数名 | 含义 |
|---|---|
| sum() | 求和 |
| mean() | 求平均值 |
| var() | 方差 |
| sd() | 标准差 |
| min() | 最小值 |
| max() | 最大值 |
| range() | 取值范围(二维向量,最大值和最小值) |
| weighted.mean() | 加权平均数 |
| median() | 中位数 |
| sort() | 排序 |
| summary( ) | 常用来展示详细结果,可以提供最小值、最大值、四分位数和数值型变 量的均值,以及因子向量和逻辑型向量的频数统计等 |
> sum(a)
[1] 21
> var(a)
[1] 3.5
> sd(a)
[1] 1.870829
> range(a)
[1] 1 6
> range(1:8)
[1] 1 8
生成有间隙的等差数列,可以用 seq 函数:
> seq(1, 9, 2)
[1] 1 3 5 7 9
seq 还可以生成从 m 到 n 的等差数列,只需要指定 m, n 以及数列的长度:
> seq(0, 1, length.out=3)
[1] 0.0 0.5 1.0
rep 是 repeat(重复)的意思,可以用于产生重复出现的数字序列:
> rep(0, 5)
[1] 0 0 0 0 0
逻辑向量主要用于向量的逻辑运算 , which 函数是逻辑型向量处理函数 , 可以用于筛选需要的数据的下标
> c(11, 12, 13) > 12
[1] FALSE FALSE TRUE
> a = c(11, 12, 13)
> b = a > 12
> print(b)
[1] FALSE FALSE TRUE
> which(b)
[1] 3
> vector = c(10, 40, 78, 64, 53, 62, 69, 70)
> print(vector[which(vector >= 60 & vector < 70)])
[1] 64 62 69
类似的函数还有 all 和 any , all() 用于检查逻辑向量是否全部为 TRUE,any() 用于检查逻辑向量是否含有 TRUE。
> all(c(TRUE, TRUE, TRUE))
[1] TRUE
> all(c(TRUE, TRUE, FALSE))
[1] FALSE
> any(c(TRUE, FALSE, FALSE))
[1] TRUE
> any(c(FALSE, FALSE, FALSE))
[1] FALSE
字符串
在 Windows 计算机上实现,使用的是 GBK 编码标准,所以一个中文字符是两个字节,如果在 UTF-8 编码的计算机上运行,单个中文字符的字节长度应该是 3。
- 单引号字符串中可以包含双引号。
- 单引号字符串中不可以包含单引号。
- 双引号字符串中可以包含单引号。
- 双引号字符串中不可以包含双引号。
> toupper("Runoob") # 转换为大写
[1] "RUNOOB"
> tolower("Runoob") # 转换为小写
[1] "runoob"
> nchar("中文", type="bytes") # 统计字节长度
[1] 4
> nchar("中文", type="char") # 总计字符数量
[1] 2
> substr("123456789", 1, 5) # 截取字符串,从 1 到 5
[1] "12345"
> substring("1234567890", 5) # 截取字符串,从 5 到结束
[1] "567890"
> as.numeric("12") # 将字符串转换为数字
[1] 12
> as.character(12.34) # 将数字转换为字符串
[1] "12.34"
> strsplit("2019;10;1", ";") # 分隔符拆分字符串
[[1]]
[1] "2019" "10" "1"
> gsub("/", "-", "2019/10/1") # 替换字符串
[1] "2019-10-1"
#R 支持 perl 语言格式的正则表达式
> gsub("[[:alpha:]]+", "$", "Two words")
[1] "$ $"
paste()
paste() 函数用于使用指定对分隔符来对字符串进行连接,默认对分隔符为空格
paste(..., sep = " ", collapse = NULL)
- … : 字符串列表
- sep : 分隔符,默认为空格
- collapse : 两个或者更多字符串对象根据元素对应关系拼接到一起,在字符串进行连接后,再使用 collapse 指定对连接符进行连接
a <- "Google"
b <- 'Runoob'
c <- "Taobao"
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(letters[1:6],1:6, sep = "", collapse = "="))
paste(letters[1:6],1:6, collapse = ".")
[1] "Google Runoob Taobao"
[1] "Google-Runoob-Taobao"
[1] "a1=b2=c3=d4=e5=f6"
[1] "a 1.b 2.c 3.d 4.e 5.f 6"
format() 函数
format() 函数用于格式化字符串,format() 可作用于字符串或数字。
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))
- x : 输入对向量
- digits : 显示的位数
- nsmall : 小数点右边显示的最少位数
- scientific : 设置科学计数法
- width : 通过开头填充空白来显示最小的宽度
- justify:设置位置,显示可以是左边、右边、中间等。
# 显示 9 位,最后一位四舍五入
result <- format(23.123456789, digits = 9)
print(result)
# 使用科学计数法显示
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# 小数点右边最小显示 5 位,没有的以 0 补充
result <- format(23.47, nsmall = 5)
print(result)
# 将数字转为字符串
result <- format(6)
print(result)
# 宽度为 6 位,不够的在开头添加空格
result <- format(13.7, width = 6)
print(result)
# 左对齐字符串
result <- format("Runoob", width = 9, justify = "l")
print(result)
# 居中显示
result <- format("Runoob", width = 10, justify = "c")
print(result)
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Runoob "
[1] " Runoob "
nchar()
nchar() 函数用于计数字符串或数字列表的长度。
nchar(x)
- x : 向量或字符串
矩阵
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,dimnames = NULL)
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)
- data 向量,矩阵的数据
- nrow 行数
- ncol 列数
- byrow 逻辑值,为 FALSE 按列排列,为 TRUE 按行排列
- dimname 设置行和列的名称
向量中的值会一列一列的填充到矩阵中。如果想按行填充,需要指定 byrow 属性
| 符号 | 作用 |
|---|---|
| %*% | 矩阵乘法 |
| t(a) | a的转置矩阵 |
| solve(a) | a的逆矩阵 |
| solve(A,b) | 求解线性代数方程 |
| apply() | 函数可以将矩阵的每一行或每一列当作向量来进行操作 |
# 获取第二行
print(P[2,])
# 获取第三列
print(P[,3])
大小相同(行数列数都相同)的矩阵之间可以相互加减,具体是对每个位置上的元素做加减法
# 两个矩阵相加
result <- matrix1 + matrix2
cat("相加结果:","\n")
print(result)
# 两个矩阵相减
result <- matrix1 - matrix2
cat("相减结果:","\n")
print(result)
# 两个矩阵相乘
result <- matrix1 * matrix2
cat("相乘结果:","\n")
print(result)
# 两个矩阵相除
result <- matrix1 / matrix2
cat("相除结果:","\n")
print(result)
> vector=c(1, 2, 3, 4, 5, 6)
> matrix(vector, 2, 3)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> matrix(vector, 2, 3, byrow=TRUE)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
> m1 = matrix(vector, 2, 3, byrow=TRUE)
> m1[1,1] # 第 1 行 第 1 列
[1] 1
# 指定行列名
> m1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> colnames(m1) = c("x", "y", "z")
> m1
x y z
[1,] 1 3 5
[2,] 2 4 6
> rownames(m1) = c("a", "b")
> m1
x y z
a 1 3 5
b 2 4 6
#矩阵乘法
> m1 = matrix(c(1, 2), 1, 2)
> m2 = matrix(c(3, 4), 2, 1)
> m1 %*% m2
[,1]
[1,] 11
> A = matrix(c(1, 3, 2, 4), 2, 2)
> solve(A)
[,1] [,2]
[1,] -2.0 1.0
[2,] 1.5 -0.5
> (A = matrix(c(1, 3, 2, 4), 2, 2))
[,1] [,2]
[1,] 1 2
[2,] 3 4
> apply(A, 1, sum) # 第二个参数为 1 按行操作,用 sum() 函数
[1] 3 7
> apply(A, 2, sum) # 第二个参数为 2 按列操作
[1] 4 6
列表
列表是 R 语言的对象集合,可以用来保存不同类型的数据,可以是数字、字符串、向量、另一个列表等,当然还可以包含矩阵和函数。
R 语言创建列表使用 list() 函数。
list_data <- list("runoob", "google", c(11,22,33), 123, 51.23, 119.1)
print(list_data)
names() 函数给列表的元素命名
# 列表包含向量、矩阵、列表
list_data <- list(c("Google","Runoob","Taobao"), matrix(c(1,2,3,4,5,6), nrow = 2),
list("runoob",12.3))
# 给列表元素设置名字
names(list_data) <- c("Sites", "Numbers", "Lists")
# 显示列表
print(list_data)
$Sites
[1] "Google" "Runoob" "Taobao"
$Numbers
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
$Lists
$Lists[[1]]
[1] "runoob"
$Lists[[2]]
[1] 12.3
使用 names() 函数命名后,我们还可以使用对应名字来访问
# 列表包含向量、矩阵、列表
list_data <- list(c("Google","Runoob","Taobao"), matrix(c(1,2,3,4,5,6), nrow = 2),
list("runoob",12.3))
# 给列表元素设置名字
names(list_data) <- c("Sites", "Numbers", "Lists")
# 显示列表
print(list_data[1])
# 访问列表的第三个元素
print(list_data[3])
# 访问第一个向量元素
print(list_data$Numbers)
$Sites
[1] "Google" "Runoob" "Taobao"
$Lists
$Lists[[1]]
[1] "runoob"
$Lists[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
操作列表元素
# 列表包含向量、矩阵、列表
list_data <- list(c("Google","Runoob","Taobao"), matrix(c(1,2,3,4,5,6), nrow = 2),
list("runoob",12.3))
# 给列表元素设置名字
names(list_data) <- c("Sites", "Numbers", "Lists")
# 添加元素
list_data[4] <- "新元素"
print(list_data[4])
# 删除元素
list_data[4] <- NULL
# 删除后输出为 NULL
print(list_data[4])
# 更新元素
list_data[3] <- "我替换来第三个元素"
print(list_data[3])
[[1]]
[1] "新元素"
$<NA>
NULL
$Lists
[1] "我替换来第三个元素"
c()合并列表
# 创建两个列表
list1 <- list(1,2,3)
list2 <- list("Google","Runoob","Taobao")
# 合并列表
merged.list <- c(list1,list2)
# 显示合并后的列表
print(merged.list)
unlist() 列表转向量
# 创建列表
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# 转换为向量
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# 两个向量相加
result <- v1+v2
print(result)
数组
array(data = NA, dim = length(data), dimnames = NULL)
- data 向量,数组元素。
- dim 数组的维度,默认是一维数组。
- dimnames 维度的名称,必须是个列表,默认情况下是不设置名称的。
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# 创建数组 3 行 3 列的的二维数组(立体)
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# 创建数组,并设置各个维度的名称
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,matrix.names))
print(result)
# 显示数组第二个矩阵中第三行的元素
print(result[3,,2])
# 显示数组第一个矩阵中第一行第三列的元素
print(result[1,3,1])
# 输出第二个矩阵
print(result[,,2])
操作数组元素
# 创建两个不同长度的向量
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# 创建数组
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# 创建两个不同长度的向量
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector1,vector2),dim = c(3,3,2))
# 从数组中创建矩阵
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# 矩阵相加
result <- matrix1+matrix2
print(result)
apply() 元素对数组元素进行跨维度计算
apply(x, margin, fun)
- x 数组
- margin 数据名称
- fun 计算函数
# 计算数组中所有矩阵第一行的数字之和
result <- apply(new.array, c(1), sum)
print(result)
因子
factor() 因子用于存储不同类别的数据类型
factor(x = character(), levels, labels = levels,
exclude = NA, ordered = is.ordered(x), nmax = NA)
- x:向量。
- levels:指定各水平值, 不指定时由x的不同值来求得。
- labels:水平的标签, 不指定时用各水平值的对应字符串。
- exclude:排除的字符。
- ordered:逻辑值,用于指定水平是否有序。
- nmax:水平的上限数量。
x <- c("男", "女", "男", "男", "女")
sex <- factor(x)
print(sex)
print(is.factor(sex))
[1] 男 女 男 男 女
Levels: 男 女
[1] TRUE
x <- c("男", "女", "男", "男", "女",levels=c('男','女'))
sex <- factor(x)
print(sex)
print(is.factor(sex))
levels1 levels2
男 女 男 男 女 男 女
Levels: 男 女
[1] TRUE
因子水平标签
接下来我们使用 labels 参数为每个因子水平添加标签,labels 参数的字符顺序,要和 levels 参数的字符顺序保持一致
sex=factor(c('f','m','f','f','m'),levels=c('f','m'),labels=c('female','male'),ordered=TRUE)
print(sex)
[1] female male female female male
Levels: female < male
生成因子水平
我们可以使用 gl() 函数来生成因子水平,语法格式如下:
gl(n, k, length = n*k, labels = seq_len(n), ordered = FALSE)
- n: 设置 level 的个数
- k: 设置每个 level 重复的次数
- length: 设置长度
- labels: 设置 level 的值
- ordered: 设置是否 level 是排列好顺序的,布尔值。
v <- gl(3, 4, labels = c("Google", "Runoob","Taobao"))
print(v)
[1] Google Google Google Google Runoob Runoob Runoob Runoob Taobao Taobao
[11] Taobao Taobao
Levels: Google Runoob Taobao
数据框

data.frame() 函数来创建R 语言数据框
data.frame(…, row.names = NULL, check.rows = FALSE,
check.names = TRUE, fix.empty.names = TRUE,
stringsAsFactors = default.stringsAsFactors())
- …: 列向量,可以是任何类型(字符型、数值型、逻辑型),一般以 tag = value 的形式表示,也可以是 value。
- row.names: 行名,默认为 NULL,可以设置为单个数字、字符串或字符串和数字的向量。
- check.rows: 检测行的名称和长度是否一致。
- check.names: 检测数据框的变量名是否合法。
- fix.empty.names: 设置未命名的参数是否自动设置名字。
- stringsAsFactors: 布尔值,字符是否转换为因子,factory-fresh 的默认值是 TRUE,可以通过设置选项(stringsAsFactors=FALSE)来修改。
table = data.frame(
姓名 = c("张三", "李四"),
工号 = c("001","002"),
月薪 = c(1000, 2000)
)
print(table) # 查看 table 数据
姓名 工号 月薪
1 张三 001 1000
2 李四 002 2000
str() 函数展示数据框
summary()显示概要信息
# 获取数据结构
str(table)
# 显示概要
print(summary(table))
'data.frame': 2 obs. of 3 variables:
$ 姓名: chr "张三" "李四"
$ 工号: chr "001" "002"
$ 月薪: num 1000 2000
姓名 工号 月薪
Length:2 Length:2 Min. :1000
Class :character Class :character 1st Qu.:1250
Mode :character Mode :character Median :1500
Mean :1500
3rd Qu.:1750
Max. :2000
# 添加部门列
table$部门 <- c("运营","技术","编辑")
# 提取指定的列
result <- data.frame(table$姓名,table$月薪)
print(result)
# 提取前面两行
print("---输出前面两行----")
result <- table[1:2,]
print(result)
# 读取第 2 、3 行的第 1 、2 列数据:
result <- table[c(2,3),c(1,2)]
print(result)
cbind() 函数将多个向量合成一个数据框
# 创建向量
sites <- c("Google","Runoob","Taobao")
likes <- c(222,111,123)
url <- c("www.google.com","www.runoob.com","www.taobao.com")
# 将向量组合成数据框
addresses <- cbind(sites,likes,url)
# 查看数据框
print(addresses)
数据重塑
合并数据框
merge() 函数
# S3 方法
merge(x, y, …)
# data.frame 的 S3 方法
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE,
incomparables = NULL, …)
- x, y: 数据框
- by, by.x, by.y:指定两个数据框中匹配列名称,默认情况下使用两个数据框中相同列名称。
- all:逻辑值; all = L 是 all.x = L 和 all.y = L 的简写,L 可以是 TRUE 或 FALSE。
- all.x:逻辑值,默认为 FALSE。如果为 TRUE, 显示 x 中匹配的行,即便 y 中没有对应匹配的行,y 中没有匹配的行用 NA 来表示。
- all.y:逻辑值,默认为 FALSE。如果为 TRUE, 显示 y 中匹配的行,即便 x 中没有对应匹配的行,x 中没有匹配的行用 NA 来表示。
- sort:逻辑值,是否对列进行排序。
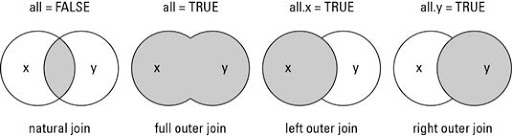
- Natural join 或 INNER JOIN:如果表中有至少一个匹配,则返回行
- Left outer join 或 LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- Right outer join 或 RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- Full outer join 或 FULL JOIN:只要其中一个表中存在匹配,则返回行
数据整合和拆分
melt() :宽格式数据转化成长格式。
cast() :长格式数据转化成宽格式。
# 安装库,MASS 包含很多统计相关的函数,工具和数据集 install.packages("MASS", repos = "https://mirrors.ustc.edu.cn/CRAN/") # melt() 和 cast() 函数需要对库 install.packages("reshape2", repos = "https://mirrors.ustc.edu.cn/CRAN/") install.packages("reshape", repos = "https://mirrors.ustc.edu.cn/CRAN/")
melt(data, ..., na.rm = FALSE, value.name = "value")
- data:数据集。
- …:传递给其他方法或来自其他方法的其他参数。
- na.rm:是否删除数据集中的 NA 值。
- value.name 变量名称,用于存储值
# 载入库
library(MASS)
library(reshape2)
library(reshape)
dcast(
data,
formula,
fun.aggregate = NULL,
...,
margins = NULL,
subset = NULL,
fill = NULL,
drop = TRUE,
value.var = guess_value(data)
)
acast(
data,
formula,
fun.aggregate = NULL,
...,
margins = NULL,
subset = NULL,
fill = NULL,
drop = TRUE,
value.var = guess_value(data)
)
- data:合并的数据框。
- formula:重塑的数据的格式,类似 x ~ y 格式,x 为行标签,y 为列标签 。
- fun.aggregate:聚合函数,用于对 value 值进行处理。
- margins:变量名称的向量(可以包含"grand_col" 和 “grand_row”),用于计算边距,设置 TURE 计算所有边距。
- subset:对结果进行条件筛选,格式类似 subset = .(variable==“length”)。
- drop:是否保留默认值。
- value.var:后面跟要处理的字段。
包
| 函数 | 作用 |
|---|---|
| .libPaths() | 查看 R 包的安装目录 |
| library() | 查看已安装的包 |
| search() | 查看已载入的包 |
| install.packages(“要安装的包名”) install.packages(“./XML_3.98-1.3.zip”) install.packages(“XML”, repos = “https://mirrors.ustc.edu.cn/CRAN/”) | 安装新包 |
| library(“包名”) | 使用包 |
| update.packages( ) | 更新已经安装的包 |
| library(ggplot2) | 要在R会话中使用它,还需要使用此命令载入这个包 |
| help(package=“package_name”) | 输出包的简短描述和包中的函数名称和数据集名称的列表 |
文件
CSV
CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号 是一种非常流行的表格存储文件格式,这种格式适合储存中型或小型数据规模的数据
id,name,url,likes
1,Google,www.google.com,111
2,Runoob,www.runoob.com,222
3,Taobao,www.taobao.com,333
CSV 用逗号来分割列,如果数据中含有逗号,就要用双引号将整个数据块包括起来
CSV 文件最后一行需要保留一个空行,不然执行程序会有警告信息
#读取 CSV 文件
data <- read.csv("sites.csv", encoding="UTF-8")
print(data)
print(is.data.frame(data)) # 查看是否是数据框
print(ncol(data)) # 列数
print(nrow(data)) # 行数
# likes 为 222 的数据
retval <- subset(data, likes == 222)
print(retval)
read.table() read.csv()
>df = read.table(file="test.txt", header=TRUE)
>df = read.csv(file="test.csv", header=TRUE)
write.table() write.csv()
>write.table(df, file="test2.txt")
>write.csv(df, file="test2.csv")
>write.csv(df, file="D:/Data/test2.csv")
条件语句等于使用 == , 多个条件使用 & 分隔符
# likes 大于 1 name 为 Runoob 的数据
retval <- subset(data, likes > 1 & name=="Runoob")
print(retval)
data <- read.csv("sites.csv", encoding="UTF-8")
# likes 为 222 的数据
retval <- subset(data, likes == 222)
# 写入新的文件
write.csv(retval,"runoob.csv")
newdata <- read.csv("runoob.csv")
print(newdata)
Excel
install.packages("RODBC")
library(RODBC)
channel<- odbcConnectExcel("myfile.xls")
mydataframe<-sqlFetch(channel ,"mysheet")
odbcClose(channel)
install.packages("xlsx", repos = "https://mirrors.ustc.edu.cn/CRAN/")
# 验证包是否安装
any(grepl("xlsx",installed.packages()))
# 载入包
library("xlsx")
library("xlsx")
# 读取 sites.xlsx 第一个工作表数据
data <- read.xlsx("sites.xlsx", sheetIndex = 1)
print(data)
XML
install.packages("XML", repos = "https://mirrors.ustc.edu.cn/CRAN/")
#查看是否安装成功
any(grepl("XML",installed.packages()))
# 载入 XML 包
library("XML")
# 设置文件名
result <- xmlParse(file = "sites.xml")
# 提取根节点
rootnode <- xmlRoot(result)
# 统计数据量
rootsize <- xmlSize(rootnode)
# 输出结果
print(result)
# 查看第 2 个节点数据
print(rootnode[2])
# 查看第 2 个节点的第 1 个数据
print(rootnode[[2]][[1]])
# 查看第 2 个节点的第 3 个数据
print(rootnode[[2]][[3]])
对输出都是 xml 格式,我们使用 xmlToList() 函数可以将文件对数据转为列表格式
# 载入 XML 包
library("XML")
# 设置文件名
result <- xmlParse(file = "sites.xml")
# 转为列表
xml_data <- xmlToList(result)
print(xml_data)
print("============================")
# 输出第一行第二列的数据
print(xml_data[[1]][[2]])
# xml 文件数据转为数据框
xmldataframe <- xmlToDataFrame("sites.xml")
print(xmldataframe)
JSON
install.packages("rjson", repos = "https://mirrors.ustc.edu.cn/CRAN/")
# 载入 rjson 包
library("rjson")
# 获取 json 数据
result <- fromJSON(file = "sites.json")
# 输出结果
print(result)
print("===============")
# 输出第 1 列的结果
print(result[1])
print("===============")
# 输出第 2 行第 2 列的结果
print(result[[2]][[2]])
as.data.frame() 函数将 json 文件数据可以转为数据框类
# 载入 rjson 包
library("rjson")
# 获取 json 数据
result <- fromJSON(file = "sites.json")
# 转为数据框
json_data_frame <- as.data.frame(result)
print(json_data_frame)
MySQL
install.packages("RMySQL", repos = "https://mirrors.ustc.edu.cn/CRAN/")
install.packages("RMariaDB", repos = "https://mirrors.ustc.edu.cn/CRAN/")
library(RMySQL)
# dbname 为数据库名,这边的参数请根据自己实际情况填写
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'test',host = 'localhost')
# 查看数据
dbListTables(mysqlconnection)
library(RMySQL)
# 查询 sites 表,增删改查操作可以通过第二个参数的 SQL 语句来实现
result = dbSendQuery(mysqlconnection, "select * from sites")
# 获取前面两行数据
data.frame = fetch(result, n = 2)
print(data.fame)
数据输出
生成制表符分隔的文本文件
>write.table(mydata, "c:/mydata.txt", sep="\t")
转换成Excel表格
>library(xlsReadWrite)
>write.xls(mydata, "c:/mydata.xls")
到SAS
>library(foreign)
>write.foreign(mydata,"c:/mydata.txt","c:/mydata.sas", package="SAS")
绘图
饼图
pie(x, labels = names(x), edges = 200, radius = 0.8,
clockwise = FALSE, init.angle = if(clockwise) 90 else 0,
density = NULL, angle = 45, col = NULL, border = NULL,
lty = NULL, main = NULL, …)
- x: 数值向量,表示每个扇形的面积。
- labels: 字符型向量,表示各扇形面积标签。
- edges: 这个参数用处不大,指的是多边形的边数(圆的轮廓类似很多边的多边形)。
- radius: 饼图的半径。
- main: 饼图的标题。
- clockwise: 是一个逻辑值,用来指示饼图各个切片是否按顺时针做出分割。
- angle: 设置底纹的斜率。
- density: 底纹的密度。默认值为 NULL。
- col: 是表示每个扇形的颜色,相当于调色板。
饼图设置标题,中文字体需要设置字体参数 family=‘GB1’
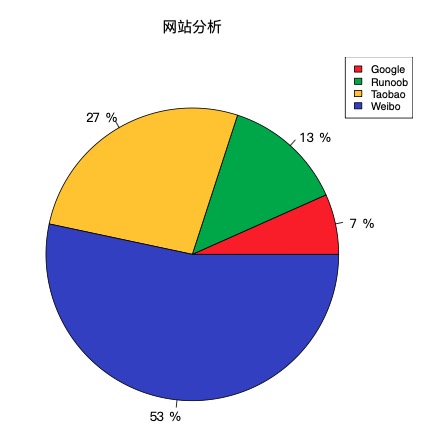
# 数据准备
info = c(1, 2, 4, 8)
# 命名
names = c("Google", "Runoob", "Taobao", "Weibo")
# 涂色(可选)
cols = c("#ED1C24","#22B14C","#FFC90E","#3f48CC")
# 计算百分比
piepercent = paste(round(100*info/sum(info)), "%")
# 绘图
pie(info, labels=piepercent, main = "网站分析", col=cols, family='GB1')
# 添加颜色样本标注
legend("topright", names, cex=0.8, fill=cols)
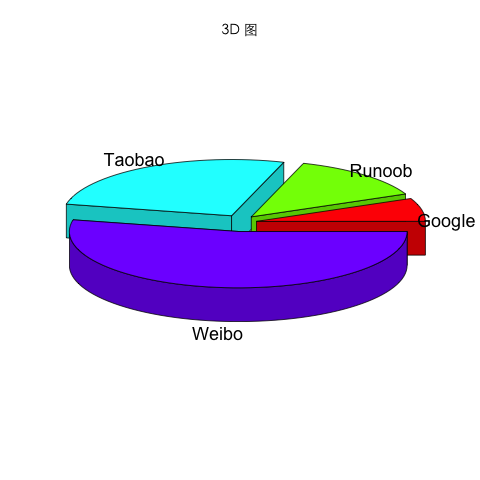
install.packages("plotrix", repos = "https://mirrors.ustc.edu.cn/CRAN/")
# 载入 plotrix
library(plotrix)
# 数据准备
info = c(1, 2, 4, 8)
# 命名
names = c("Google", "Runoob", "Taobao", "Weibo")
# 涂色(可选)
cols = c("#ED1C24","#22B14C","#FFC90E","#3f48CC")
# 设置文件名,输出为 png
png(file = "3d_pie_chart.png")
# 绘制 3D 图,family 要设置你系统支持的中文字体库
pie3D(info,labels = names,explode = 0.1, main = "3D 图",family = "STHeitiTC-Light")
条形图
barplot(H,xlab,ylab,main, names.arg,col,beside)
- H 向量或矩阵,包含图表用的数字值,每个数值表示矩形条的高度
- xlab x 轴标签
- ylab y 轴标签
- main 图表标题
- names.arg 每个矩形条的名称
- col 每个矩形条的颜色
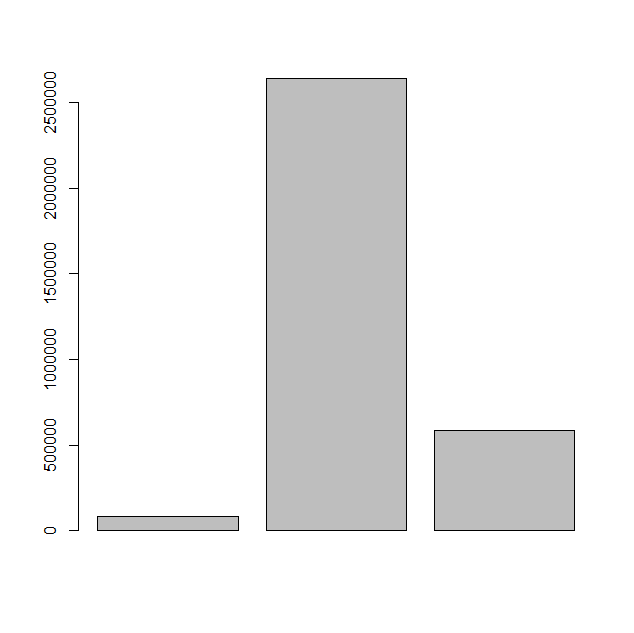
# 准备一个向量
cvd19 = c(83534,2640626,585493)
# 显示条形图
barplot(cvd19)
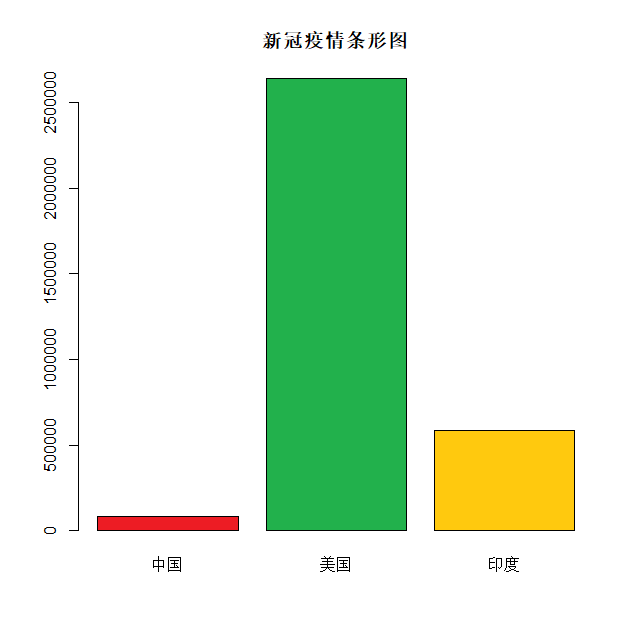
中文字体需要设置字体参数 family=‘GB1’:
cvd19 = c(83534,2640626,585493)
barplot(cvd19,
main="新冠疫情条形图",
col=c("#ED1C24","#22B14C","#FFC90E"),
names.arg=c("中国","美国","印度"),
family='GB1'
)
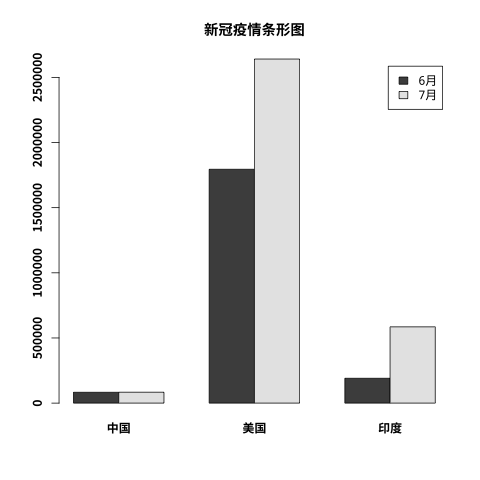
library(showtext);
font_add("SyHei", "SourceHanSansSC-Bold.otf");
cvd19 = matrix(
c(83017, 83534, 1794546, 2640626, 190535, 585493),
2, 3
)
# 设置文件名,输出为 png
png(file = "runoob-bar-1.png")
#加载字体
showtext_begin();
colnames(cvd19) = c("中国", "美国", "印度")
rownames(cvd19) = c("6月", "7月")
barplot(cvd19, main = "新冠疫情条形图", beside=TRUE, legend=TRUE, family='SyHei')
# 去掉字体
showtext_end();
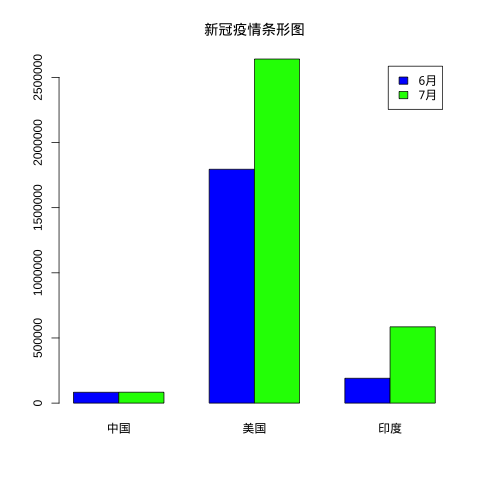
library(plotrix)
library(showtext);
font_add("SyHei", "SourceHanSansSC-Bold.otf");
cvd19 = matrix(
c(83017, 83534, 1794546, 2640626, 190535, 585493),
2, 3
)
# 设置文件名,输出为 png
png(file = "runoob-bar-2.png")
#加载字体
showtext_begin();
colnames(cvd19) = c("中国", "美国", "印度")
rownames(cvd19) = c("6月", "7月")
barplot(cvd19, main = "新冠疫情条形图", beside=TRUE, legend=TRUE,col=c("blue","green"), family='SyHei')
# 去掉字体
showtext_end();
函数曲线图
curve() 函数可以绘制函数的图像
curve(expr, from = NULL, to = NULL, n = 101, add = FALSE,
type = "l", xname = "x", xlab = xname, ylab = NULL,
log = NULL, xlim = NULL, …)
# S3 函数的方法
plot(x, y = 0, to = 1, from = y, xlim = NULL, ylab = NULL, …)
- expr:函数表达式
- from 和 to:绘图的起止范围
- n:一个整数值,表示 x 取值的数量
- add:是一个逻辑值,当为 TRUE 时,表示将绘图添加到已存在的绘图中。
- type:绘图的类型,p 为点、l 为直线, o 同时绘制点和线,且线穿过点。
- xname:用于 x 轴变量的名称。
- xlim 和 ylim 表示x轴和y轴的范围。
- xlab,ylab:x 轴和 y 轴的标签名称。
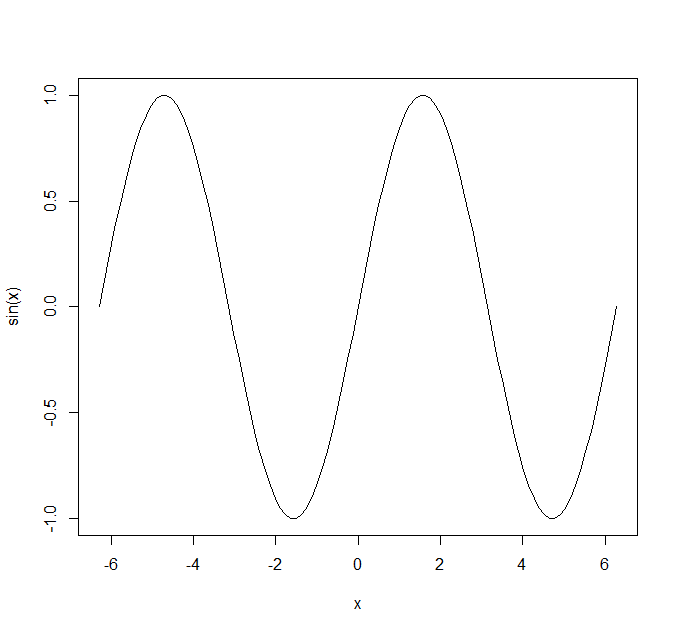
curve(sin(x), -2 * pi, 2 * pi)
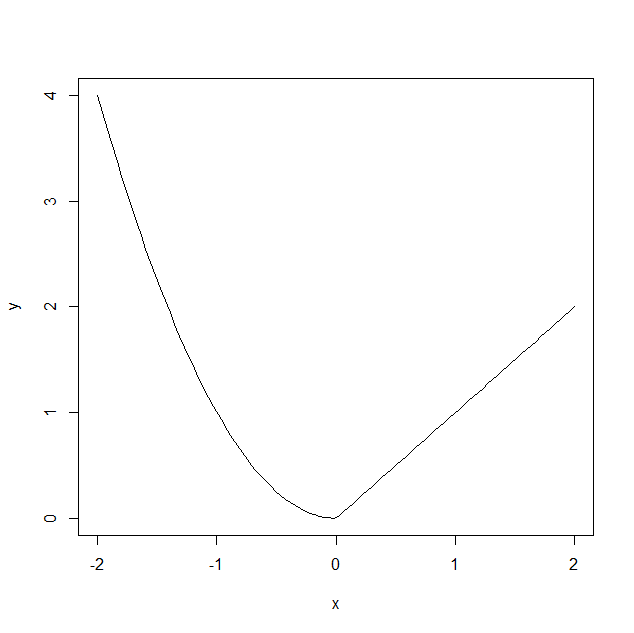
# 定义函数 f
f = function (x) {
if (x >= 0) {
x
} else {
x ^ 2
}
}
# 生成自变量序列
x = seq(-2, 2, length=100)
# 生成因变量序列
y = rep(0, length(x))
j = 1
for (i in x) {
y[j] = f(i)
j = j + 1
}
# 绘制图像
plot(x, y, type='l')
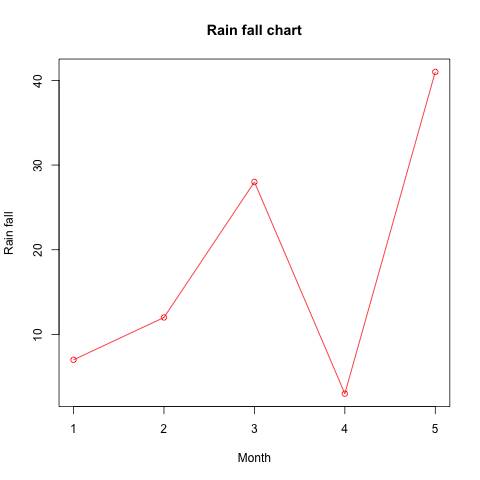
plot() 函数对向量数据进行绘图
# 向量数据
v <- c(7,12,28,3,41)
# 生成图片
png(file = "line_chart_label_colored.jpg")
# 绘图、线图颜色为红色,main 参数用于设置标题
plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
散点图
plot(x, y, type="p", main, xlab, ylab, xlim, ylim, axes)
plot(x=x轴数据,y=y轴数据,main="标题",sub="子标题"
,type="线型",xlab="x轴名称"
,ylab="y轴名
称"
,xlim = c(x轴范围,x轴范围),ylim = c(y轴范围,y轴范围))
- x 横坐标 x 轴的数据集合
- y 纵坐标 y 轴的数据集合
- type:绘图的类型,p 为点、l 为直线, o 同时绘制点和线,且线穿过点。
- main 图表标题。
- xlab、ylab x 轴和 y 轴的标签名称。
- xlim、ylim x 轴和 y 轴的范围。
- axes 布尔值,是否绘制两个 x 轴。
type 参数可选择值:
- p:点图
- l:线图
- b:同时绘制点和线
- c:仅绘制参数 b 所示的线
- o:同时绘制点和线,且线穿过点
- h:绘制出点到横坐标轴的垂直线
- s:阶梯图,先横后纵
- S:阶梯图,先纵后竖
- n: 空图
图形参数
- pch 指定绘制点时使用的符号
- cex 是一个数值,表示绘图符号相对于默认大小的缩放倍数。
- lty 指定线条类型 lwd 指定线条宽度。
- col 默认的绘图颜色。
- cex 表示相对于默认大小缩放倍数的数值。
- font 整数。用于指定绘图使用的字体样式。
- pin 以英寸表示的图形尺寸(宽和高)
- mai 以数值向量表示的边界大小, 顺序为“下、左、上、右”,单位为英寸
x<-c(10,40)
y<-c(20,60)
# 生成 png 图片
png(file = "runnob-test-plot2.png")
plot(x, y, "l") #线段
plot(x, y, "o")#线段两端圆点
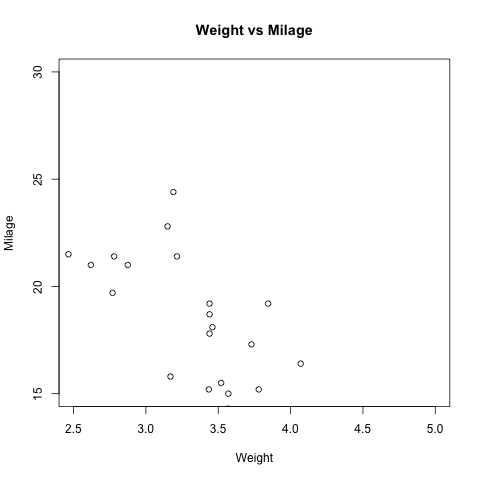
# 数据
input <- mtcars[,c('wt','mpg')]
# 生成 png 图片
png(file = "scatterplot.png")
# 设置坐标 x 轴范围 2.5 到 5, y 轴范围 15 到 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
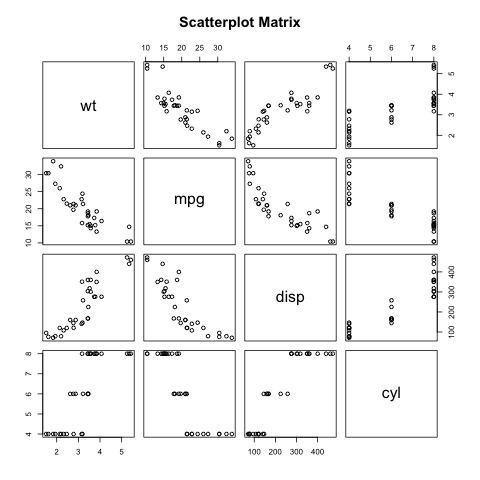
散点图矩阵
pairs(formula, data)
- formula 变量系列
- data 变量的数据集
# 输出图片
png(file = "scatterplot_matrices.png")
# 4 个变量绘制矩阵,12 个图
pairs(~wt+mpg+disp+cyl,data = mtcars, main = "Scatterplot Matrix")
plot(x, y, xlab='x=自变量', ylab='y=因变量') # 添加坐标轴标题
grid(col='grey60') # 添加网格线
axis(side=4, col.ticks='blue', lty=1) # 绘制坐标轴
abline(lm(y~x), lwd=2, col=2) # 添加回归直线
lines(lowess(y~x, f=1/6), col=4, lwd=2, lty=6) # 添加拟合曲线
mtext(expression(hat(y)==hat(beta)[0]+hat(beta)[1]*x), cex=0.9,
side=1, line=-5.3, adj=0.72) # 添加注释表达式
legend('topleft', legend=c('拟合的直线', '拟合的曲线'), lty=c(1, 6),
col=c(2, 4), cex=0.8, fill=c('red', 'blue'), box.col='grey60',
ncol=1, inset=0.02) # 添加图例
title('散点图及拟合直线和曲线\n并为图形添加新的元素',
cex.main=0.8, font.main=4) # 添加标题并换行,使用斜体字
box(col=4, lwd=2) # 添加边框
> v <- c(27, 27, 27, 28, 27, 25, 25, 28, 26, 28, 26, 28, 31, 30, 26, 26)
>hist(v) #频率直方图
>barplot(v)#条形图

